Okul ile alakalı bir proje kapsamında aynı anda üretilen N satırlık veriyi hızlı bir şekilde kayıt etmem gerekti. Bunu yapmak için en iyi yöntemi araştırırken tek bir dosyaya mı yazmak yoksa işlemleri bölüm ayrı ayrı dosyalara mı yazmak daha iyi olur diye test yapmak istedim. Sonra test biraz büyüdü işin içine veri tabanları girdi. Ekleme dışında güncelleme ve seçme işlemleri de girdi. Her ne kadar bir geliştirici olmasamda test sonuçlarını ile alakalı ufak bir yazı yazayım dedim.
Problemimiz şu şekilde çok fazla process aynı anda belirli bir satır sayısına sahip veri üretiyor. Yani t anında bir anda elimizde N tane verimiz var. Veri formatı aşağıda paylaşılmış. Verinin sonradan sorgulanabilir olup olmadığına bakmadan bir yere kayıt etmemiz lazım. En hızlı nasıl yaparız?
Örnek bir veri aşağıdaki gibi
sample = {
"id": "RANDOM_ID",
"ip": "RANDOM_IP",
"port": "RANDOM_INT",
"area_code": "RANDOM_INT",
"longitude": "RANDOM_INT",
"latitude": "RANDOM_INT",
"timestamp": "TIME",
}
Öncelikle doğru test yapabilmek adına async bir process havuzu oluşturdum. Ve process sayısını parametrik olarak ayarladım. Aynı şekilde her bir process tarafından oluşturulması planlanan veri sayısını da parametreye bağladım.
-p parametresi process sayısı
-l parametresi oluşturulan veri sayısını belirtiyor.
Sonrasında iki adet donanım ayarladım. Bir tanesi 1 cpu 8 gb ram diğeri de 8 cpu 64 gb ram.
Her bir donanıma, redis, mongo ve mysql veri tabanlarını kurdum. Mongo ve redis için örnek veriyi aynı şekilde sakladım. Mysql için aşağıdaki tabloyu kullandım.
CREATE TABLE `test` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`ip` int(10) unsigned NOT NULL,
`isp` varchar(250) NOT NULL,
`details` text NOT NULL,
PRIMARY KEY (`id`),
KEY `testid` (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=latin1;
İşletim sistemi olarak ubuntu 18.04 LTS kullanıldı.
Şunu belirteyim ki herhangi bir optimizasyon yapmadım, yani kurulumdaki varsayılan ayarlar neyse o şekilde bıraktım. Bu nedenle her bir veritabanı için en iyi senaryoları değil varsayılan ayarlardaki senaryoları test etmiş oldum.
Test kodlarının tamamını yayınladım, siberkuvvet’in github sayfasından (burası , https://github.com/siberkuvvet/dbms-benchmark/) ulaşabilirsiniz.
Veri ekleme işlemlerini 1000 adet async process ile gerçekleştirdim (-p 1000). Her bir işlemden sonra veritabanında bulunan verileri temizledim.
Her senaryoda 1000 process çalıştı, her bir process N örnek veri üretti ve çıktısını senaryoya göre kaydetti.
Senaryolardaki her test 1 cpu 8gb ram donanımda 3 kere yaptı.
Daha sonra aynı testler 3 kere 8cpu 64gb ram donanımda yapıldı.
Tüm testler benzer şekilde toplamda 2 farklı donanımda toplam 6 kere gerçekleştirildi.
Test senaryoları;
-
Her process kendi çıktısını ayrı bir dosyaya yazdı.
- Her process 1 adet veri üretti
- Her process 100 adet veri üretti
- Her process 1.000 adet veri üretti
- Her process 10.000 adet veri üretti
-
Tüm processler ürettiği veriyi tek bir dosyaya yazdı.
- Her process 1 adet veri üretti
- Her process 100 adet veri üretti
- Her process 1.000 adet veri üretti
- Her process 10.000 adet veri üretti
-
Her process kendi çıktısını REDIS veritabanına pipeline kullanarak yazdı.
- Her process 1 adet veri üretti
- Her process 100 adet veri üretti
- Her process 1.000 adet veri üretti
- Her process 10.000 adet veri üretti
-
Her process kendi çıktısını REDIS veritabanına pipeline kullanmadan yazdı.
- Her process 1 adet veri üretti
- Her process 100 adet veri üretti
- Her process 1.000 adet veri üretti
- Her process 10.000 adet veri üretti
-
Her process kendi çıktısını MYSQL veritabanına load file kullanarak yazdı.
- Her process 1 adet veri üretti
- Her process 100 adet veri üretti
- Her process 1.000 adet veri üretti
- Her process 10.000 adet veri üretti
-
Her process kendi çıktısını MYSQL veritabanına load file kullanmadan yazdı.
- Her process 1 adet veri üretti
- Her process 100 adet veri üretti
- Her process 1.000 adet veri üretti
- Her process 10.000 adet veri üretti
-
Her process kendi çıktısını Mongo veritabanına insertmany kullanarak yazdı.
- Her process 1 adet veri üretti
- Her process 100 adet veri üretti
- Her process 1.000 adet veri üretti
- Her process 10.000 adet veri üretti
-
Her process kendi çıktısını Mongo veritabanına insertmany kullanmadan yazdı.
- Her process 1 adet veri üretti
- Her process 100 adet veri üretti
- Her process 1.000 adet veri üretti
- Her process 10.000 adet veri üretti
Yukarıdaki toplam 32 (8x4) test her bir donanımda 3 kere (toplam iki donanım var yani 3x2x32) 192 kere yapıldı.
Sonuçlara geçmeden önce senaryolar hakkında bir detay vereyim.
1000 process’in tek bir dosyaya yazması veya ayrı dosyaya yazması sırasında disk I/O ve süresini gözlemledim.
Redis’de pipelining özelliği var. Her bir veriyi tek tek yazmak yerine veriyi toplu şekilde daha efektif yazmak için bu özelliği kullanarak ve kullanmayarak iki senaryo oluşturdum.
Mysql’de toplu insert işlemi en hızlı yapmanın yolu önce veriyi dosyaya yazmak sonra dosyadan Load File ile okuyarak tabloya aktarmak. Bunu niçin MYSQL’de Load File komutunda kullanılacak dizin için izin vermelisiniz. Load file kullanan ve kullanmayan iki senaryo da MYSQL insert testlerinde var.
Mongo’da çoklu veri ekleme için insertmany yapısı var. Bu aynı Redis’teki pipeline gibi. Mongo’ya veri eklemek için insertmany kullanan ve kullanmayan iki senaryo var.
Hadi sonuçları paylaşalım. Her bir sütundaki veriler tüm işlemlerin bitmesi için geçen saniyeyi belirtiyor.
Sonuçlar - Senaryoya Göre Grafikler
Grafiklerde alt satır senaryoyu çubuktaki raka saniyeyi gösteriyor.
1CPU 8gb ram (hw1) için ekleme (insert) test sonuçları
Her bir process 1 çıktı üretti.
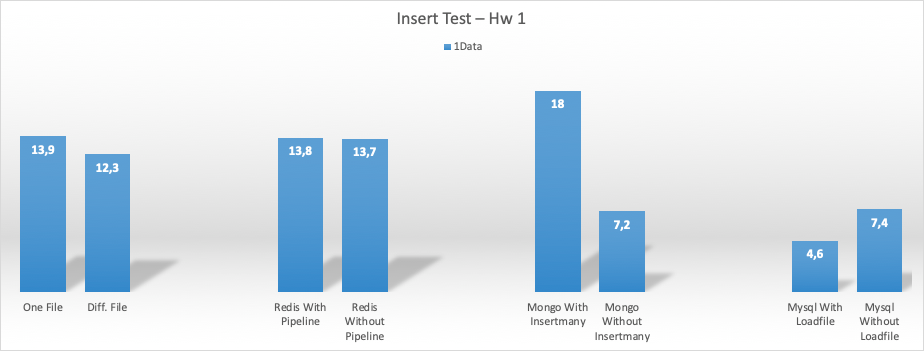
Her bir process 100 çıktı üretti.
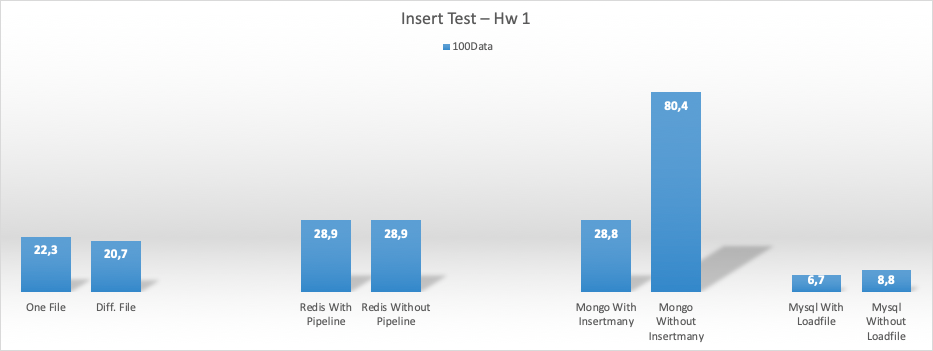
Her bir process 1000 çıktı üretti (mysql işlem yapamadı, öncekinde connectionlar kapanmamış olabilir, emin değilim ne oldu)
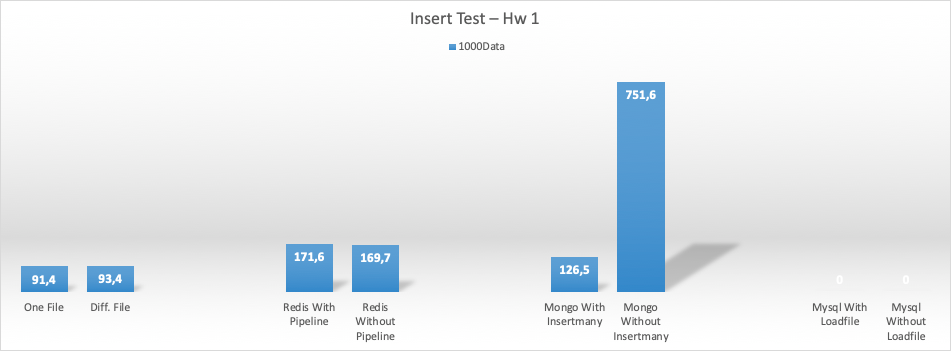
Her bir process 10.000 çıktı üretti
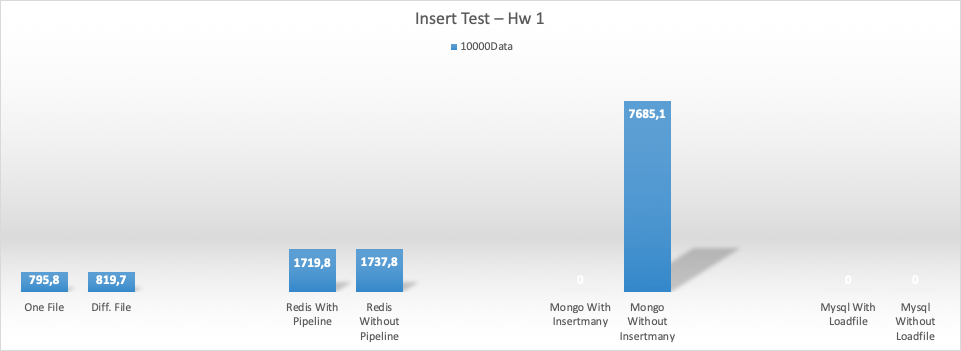
8CPU 64gb ram (hw2) için ekleme (insert) test sonuçları
Her bir process 1 çıktı üretti.
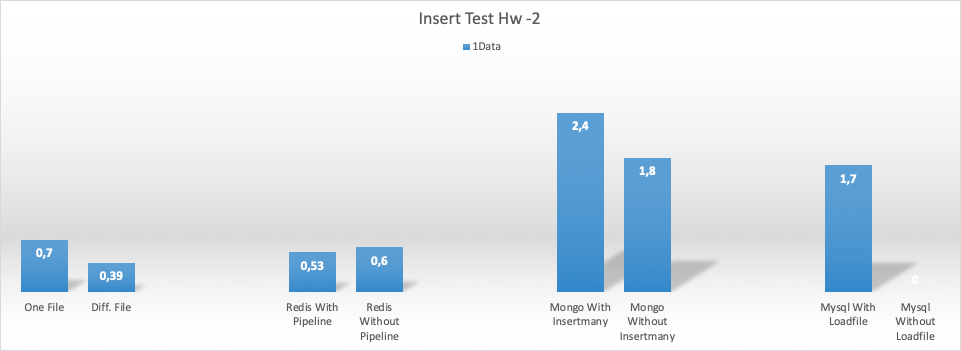
Her bir process 100 çıktı üretti.
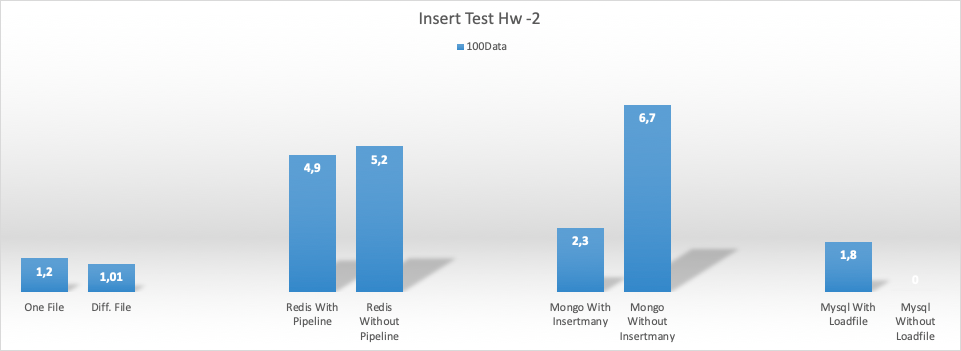
Her bir process 1000 çıktı üretti
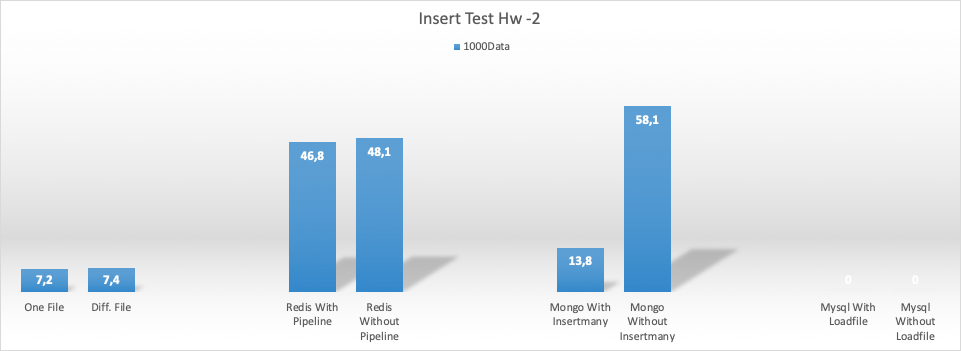
Her bir process 10000 çıktı üretti
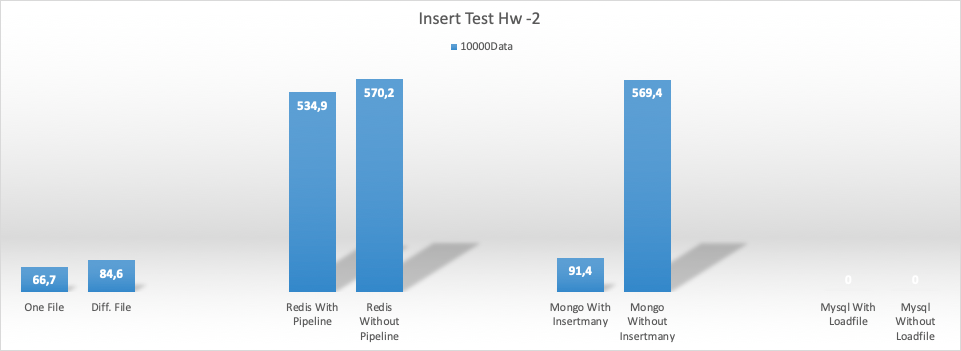
Update ve select işlemleri için önce inserti çalıştırıp sonrasında ilgili veritabanında anahtar değerlerini okuyan bir kod yazdım. Mongo ver redis’de varsayılan değeri, Mysql’da ise ID değerini index tanımlayıp bu değeri okudum.
Update ve select testlerinde 1000 process 1000 adet rastgele veriyi update etti veya veritabanındandan okudu. Test sonuçları aşağıda
Update Test Sonucu Hw1
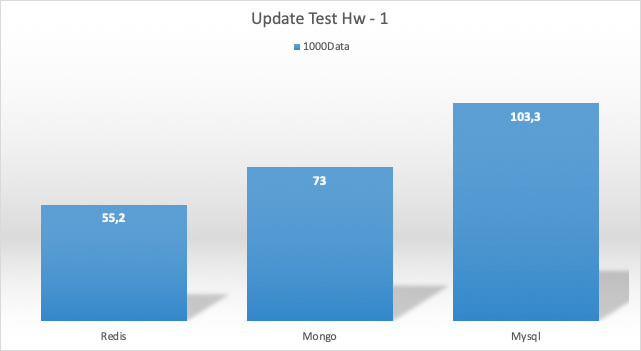
Update Test Sonucu Hw2
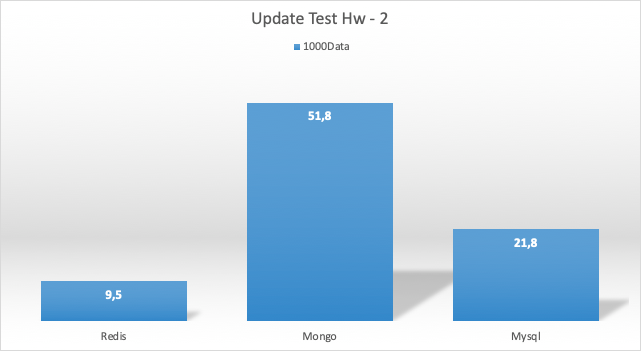
Select Test Sonucu HW 1
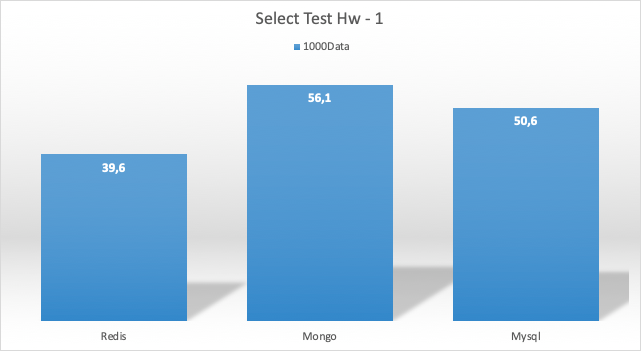
Select Test Sonucu HW 2
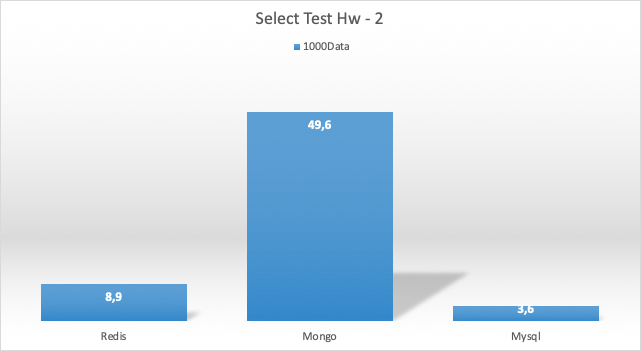
Sonuçlar
Öyle bir iş düşünün ki anlık olarak dağıtık processler tarafından sırasıyla 1.000, 100.000, 1.000.000 ve 10.000.000 satırlık veri üretsin.
Her senaryoda en hızlı şekilde kayıt etme yöntemi aynı dosyaya yazmak. Processlerin farklı dosyaya yazmasının daha yavaş olma sebebinin her dosya için file handler oluşturmak olduğunu varsayıyorum.
Mysql ile bazı testler tamamlayamadım. Sanırım connection havuzu ile alakalı bir problem oldu.
Eğer veritabanına kayıt etme sırasında düşük ram ile çalışıyorsanız, çok hızlı bir şekilde SWAP alanı kullanmaya başlıyor, bu da oldukça fena.
Bilineni doğruladık:
- Çok miktarda veriyi Mysql’e yükleyecekseniz (insert edecekseniz) load file komutu kullanın.
- Çok miktarda veriyi Redis’e yükleyecekseniz (insert edecekseniz) pipelining kullanın.
- Çok miktarda veriyi Mongo’ya yükleyecekseniz (insert edecekseniz) insert many kullanın.
Redis yeterli donanımda çok hızlı, donanım gücü işleme yetmemeye başladıkça mongo önce çıkıyor.
Mysql donanım dar boğaz olmadığı senaryolarda çok daha hızlı select query çalıştırıyor (birisi niye olduğunu yazarsa sevinirim?)
Mongo’nun ücretsiz sürümü sadece RAM kullanmıyor.
Test sonuçları yoruma açık özellikle yazıdaki soruları yorumlayan olursa sevinirim. Son olarak bu testleri bir veritabanını diğerinden daha iyi yapmaz. Belirtildiği gibi varsayılan yükleme ayarları kullanıldı.
Bu makale 0xnur tarafından yazılmış veya yayınlanmıştır.