Bilindiği gibi günümüzdeki bilişim alt yapılarını kullanan gerek son kullanıcı gerekse kurumsal sistemler anlık devasa büyüklükte veri üretiyorlar. Bu yazının yazıldığı tarih itibariyle bunlara örnek vermek gerekirse günlük atılan toplam tweet sayısı yaklaşık 500 milyon (9/5/19 tarihli istatistik :https://www.omnicoreagency.com/twitter-statistics/). 2.75 million yeni blog yazısı (https://hostingtribunal.com/blog/blog-posts-per-day/#gref) her gün internette yayınlanıyor ve facebook’un ürettiği toplam veri büyüklüğü ise günlük 4 petabyte (https://www.brandwatch.com/blog/facebook-statistics/). Üretilen bu kadar büyük veri içerisinde hem biz araştırmacılar hem de kurumlar açısından siber güvenlik ile alakalı önemli bilgiler de bulunuyor.
Bu önemli bilgiler bir zararlı yazılıma ait rapor, oltalama siteleri, zafiyet bildirimleri, yeni saldırı yöntemleri ya da sıfırıncı gün saldırıları ile alakalı olabilir. Peki bu kadar büyük veri içerisinde siber güvenlik ile ilgili ne tür çalışmalar yapabiliriz, ne olsa işimize yarar? Nasıl analiz edeceğiz?
Burada devreye metin işleme (text-mining) algoritmaları giriyor. Veri kaynağı olarak metinleri alıp, ihtiyaca yönelik analizleri gerçekleştirme işlemlerine metin işleme (text mining) adı veriliyor. Algoritmalar, kümeleme, kategorileme, duygusal analiz, özetleme gibi konular için çalışıtırılabilir.
Bu yazı da siber güvenlikte metin madenciliği ile alakalı çeşitli akademik çalışmaları ve projeleri inceleyeceğiz.
ADROIT: Android malware detection using meta-information
(https://ieeexplore.ieee.org/document/7849904)
Anroid işletim sistemine sahip cihazları hedef alan zararlı uygulamaların bulaşma yöntemlerinden biri de markete yüklenerek son kullanıcının zararlıyı indirimesidir. ANROIT çalışmasında ANROID uygulamanın meta verileri ve android manifest dosyası kullanılarak zararlı olup olmadığı tespit edilmiş.Test için Aptoide marketi kullanmışlar ve toplamda 12.360 adet uygulama indirmişler.
Öncelikle verileri zararlı ve temiz olarak ayırmışlar bunu için de virustotal kullanılmış. Manifest dosyasına ek olarak meta veriler ise şunları içeriyor: minimum sdk, OpenGL version, minimum size of screen, supported CPU types, identification of developer (organization, locality, county), rating score, number of user rate, description.
Tüm bu verileri aşağıdaki algoritmalar ile test etmişler:
-
Random Forest (RF)
-
k-Nearest Neighbours (kNN)
-
Decision Trees (DT)
-
AdaBoost (AB)
-
Bagging (B)
-
Na ̈ıve bayes (NB)
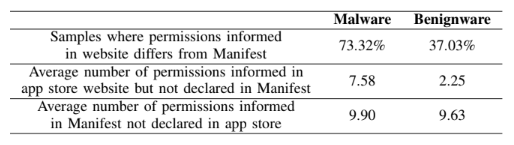
Android manifest dosyasındaki izinlerin zararlı ve temiz uygulama ile karşılaştırması çıkmış. Tablo olarak ekliyorum onu da. Sonuçlar oldukça ilginç. Temiz olarak gözüken uygulamalarda bile sitede gözüken izinler ile manifestteki izinler farklı çıkmış.
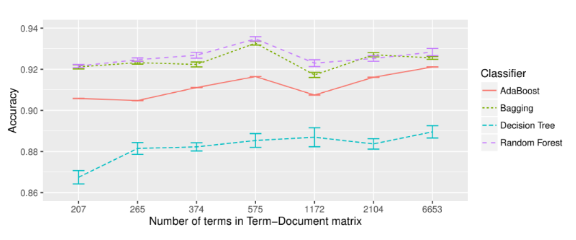
Metin madenciliği algoritmaları ile yapılan testlerin sonuçları aşağıda doğruluğu (accuracy) en yüksek random forest algoritmasında çıkmış.
Ben çalışmanın herhangi bir kodunu bulamadım. Bulursanız yorum olarak ekleyebilirsiniz.
Diğer çalışmamıza geçelim:
Detection Cybersecurity Events Noisy Short Text
(https://arxiv.org/abs/1904.05054)
Twitter’da her konuda olduğu gibi siber güvenlik ile ilgili konularında da oldukça fazla içerik mevcut. Peki tweetlerden hangilerinin siber güvenlik ile alakalı olduğunu nasıl tespit edebiliriz? Bu çalışma tam olarak bunun için yapılmış. Yapanlarda yabancı değil STM A.Ş çalışanları. Tam listeye makalenin orjinalinden ulaşabilirsiniz. Öncelikle 2015’in başından 2017’nin sonuna kadarki tarihlerde 2.5 milyonluk bir veri toplamışlar. Bunun 2bin tanesini siber güvenlik ile alakalı veya değil olarak işaretlemişler.
Kelimeleri (algoritmaları koşmak için) vektöre dökerken anlamlarını da kaybetmemek için Word2Vec metodunu kullanmışlar. Bu sayede kelimelerin sözdizimsel ve anlamsal özelliklerin saklayabilmişler. Veri içerisindeki konuyu belirlemek için de (bağlamsal vektörü oluşturmak için) Latent Dirichlet Allocation (LDA), Named Entity Recognition (NER), Information Extraction (IE) methodlarının tamamını tek bir çıktı verecek şekilde kullanmışlar.
CNN ve LSTM modellerini (architecture) hem anlamsal hem de bağlamsal vektör girdileri ile beslemişler.
Yöntemleri 0.82 başarı oranı yakalamış.
IDENTIFYING SECURITY BUG REPORTS VIA TEXT MINING
(https://ieeexplore.ieee.org/document/5463340)
Yazılım geliştirilirken çıkan hataların düzenli olarak takibi ve önceliklendirilmesi için genellikle bir hata yönetim sistemi kullanılır (bugzilla gibi). Bu hataların önceliklendirilmesinde, hatayı giren kullanıcı tarafından verilen “güvenlik ile alakalı” anlamında gelen bir etiket de kullanılır. Eğer güvenlik ile alakalı ise hataya öncelik verilir. Fakat kullanıcıların farkındalık eksikliği nedeniyle “güvenlik ile alakalı” etiketini kullanmadığı durumlar oldukça fazladır. Bu durumda bir bug’ın metin madenciliği teknikleri kullanılarak güvenlik ile alakalı olduğunu tespit etmek ve o buga öncelik vermek önem kazanıyor. Çalışmada da bunu yapmışlar. Metin madenciliği için SAS Text Mining yazılımını kullanmışlar.
Veri seti olarak CISCO’nun 4 senelik güvenlik ile alakalı olarak işaretlenen hatalarını kullanmışlar. Sonra da oluşturulan modeli güvenlik ile alakalı olmayan hata raporlarına uygulamışlar.
Öncelikle algoritmaları koşmak için gerekli veri setinde güvenlik ile alakalı veya güvenlik ile alakalı değil olarak etiketleme yapılmış. CISCO’nun veritabanındaki hata raporlarında bu etiketleme yoksa yardım alarak bu işi elle yapmışlar (CISCO çalışanları da dahil).
Daha sonra SAS yazılımında kullanılan, start, stop ve synonim adlı üç liste hazırlayıp yazılımla - benim makalede ismini bulamadığım- algoritmayı koşmuşlar.
Sonuçta oldukça fazla sayıda “güvenlik ile alakalı olmayan” hata raporunun aslında “güvenlik ile alakalı” olduğunu görmüşler. Doğruluğu arttırmak için modeli yeni “güvenlik ile alakalı” hata raporlarının kullanılması tavsiye edilmiş. Fakat farklı türdeki zafiyetlerin olabileceği sistemlerde bu modelin uygulanması önerilmiyor.
TEXT MINING for Security Threat Detection : Discovering Hidden Information In Unstructured Log Messages
(https://ieeexplore.ieee.org/document/7860492)
Aslında adından herşeyi anlatıyor. SIEM üzerinden akan verilerin çokluğu, f/p oranı, iz kayıtlarının yapısal olmaması nedeniyle kaybedilen veriler ciddi bir sorun. Yapısal olmayan veriden kasıt şu:
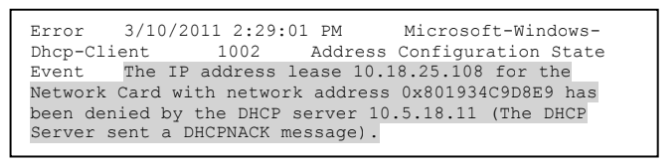
SIEM her ne kadar yapısal verileri toplayıp, özetlese de bu tarz yapısal olmayan verileri kaçırabiliyor. Bu çalışmanın amacı da yapısal olmayan iz kayıtlarındaki siber güvenlik ile alakalı verilerin metin madenciliği ve doğal dil işleme yöntemleri ile analiz edilerek değerlendirilmesi olmuş.
Veri seti olarak SKAION 2006 IARPA verisetini kullanmışlar. Bu veri seti çeşitli zararlı işlemlerin iz kayıtları ve ağ verilerini içerdiğinden üzerinde bir özetleme yapmışlar.
Çalışmaları temel olarak 3 ana maddeyi içeriyor bunlar aşağıdaki gibi :
-
Öncelikle yapısal olmayan iz kayıtları verilerini çeşitli sınıflandırma yöntemlerini kullanarak analiz etmişler. Bunun amacı da en iyi sınıflandırma yöntemini bulmak.
-
Tehdit tespiti yapabilmek için iz kayıtlarındaki özelliklerini belirlemişler. Bir üst madde ki sınıflandırma yöntemlerini sadece belirlenen özellikler ile tekrar deneme yapmışlar. Ayrıca belirlenen özellikler + iz kayıt mesajının tamamı şeklinde tekrar bir deneme yapmışlar.
-
Sonuçların analizi
İz kayıtlarındaki bilinen (hostname, id, timestamp, gibi) değerleri analiz etmek için named entity recognition ile generic text extract yöntemlerini kullanmışlar.
Her algoritmayı farklı veri setlerinde denedikleri için tek tek durumlarını belirlemek yerine en başarılı senaryoya atlıyorum.
İz kayıt mesajı ile bu mesajın içerisindeki belirlenen özellikleri TF-IDF ve IG özellik seçimi yöntemleri ile belirlemişler. Random ağaç, J48 ağaç algoritmaları en başarılı sonucu vermiş. Başarı oranı her biri için yaklaşık olarak 0.68. Hem iz kayıt mesajının tamamı hem de içerisindeki özellikler ile çalışan algoritmanın akan veriler için biraz yavaş olabileceği belirtilmiş. Bu nedenle sadece belirlenen özelliklerin kullanımı ile bile başarılı sonuçlar alınabileceği eklenmiş.
Malware Detection By Text And Data Mining
(https://www.researchgate.net/publication/269328525_Malware_detection_by_text_and_data_mining)
Bu makale benim de ufak bir deneme yaptığım konu ile alakalı. Zararlı yazılımların API Call’ları üzerinde metin madenciliği ile Windows üzerinde çalışan dosyaların zararlı olup olmadığının analizi üzerine çalışılmış. Veri seti olarak CSMINING grubuna ait bir veri seti kullanmışlar.
Öncelikle veri setinden özellik çıkararak mutual information yöntemini kullanmışlar. Metin madenciliği teknikleri olarak da Decision Tree, Multi Layer Perceptron, Support Vector Machine, Probabilistic Neural Network , Group Method for data handling algoritmaları kullanılmış.
Bu çalışmanın başarı oranı ise oldukça iddialı %98.50.
Sırada yine bir metin madenciliği ile zararlı android uygulamalarını tespit çalışması var. Fakat yöntem oldukça farklı.
Dendroid: A Text Mining Approach To Analyzing And Classifying Code Structures In Android Malware Families
(https://www.sciencedirect.com/science/article/pii/S0957417413006088)
Android zararlı uygulamalarının sayıları sürekli artsada benzer türlerdeki zararlılar oldukça fazla. Benzer türlerden kasıt, aynı zararlı aktivite, aynı kod yapısı, tekniklerde benzerlikler vb. Farklı olan içerisindeki bazı anahtar değerleri ve/veya komuta kontrol merkezleri gibi düşünebilirsiniz.
Veri seti olarak Android Genome Malware projesi içerisindeki veri setini kullanmışlar. Bu veri seti içerisinde 1247 adet zararlı android uygulama var. Bu uygulamalarda toplam 49 farklı zararlı ailesine ait. 16 adet zararlı ailesi yalnızca tek bir uygulama içerdiğinden dolayı bu uygulamaları kaldırmışlar.
TF-IDF ve Cosign similarity gibi temel teknikler kullansalarda oldukça başarılı olmuşlar. Bunun nedeni de kullandıkları veri kümesi.
Her bir uygulamayı analiz ederek içerisindeki statik akışı analiz etmişler. Örneğin If kodu varsa I, String varsa S, Goto varsa G Return varsa R gibi etiketleme yapıp aynı gen yapısı gibi bir veri çıkarmışlar.
Örnek resim aşağıda, CC1 birinci uygulamanın analiz sonucu, CC2 ikinci, CC3 üçüncü.
u analizlere ek olarak, zararlı yazılım ailesine ait veri kümesinin tamamı ve ilgili zararlı ailesine ait android uygulamalarda kesişen veri dizisini de tespit edip TF-IDF matrixinde kullanmışlar.
Toplamda %5.74 lük bir hata oranı ile bir uygulamayı ilgili zararlı yazılım ailesi ile eşleştirmişler.
Genel bir çalışma derlemesi oldu, umarım keyifle okumuşsunuzdur.
Herkese iyi çalışmalar dilerim.